Für das gelegentliche Rechnen liefern die meisten Desktops irgendeine Art von Calculator-Anwendung und aus irgend einem Grund imitieren diese meistens Taschenrechner aus dem Real-Life, und zwar immer diese billigen Teile die nichts können. Besonders nervig ist, dass diese immer nur Zwischenergebnisse anzeigen und man nicht eine längere Expression eingeben kann die dann auch mathematisch korrekt ausgewertet wird.
Neben all den unbrauchbaren Rechnern, wie der von Windows oder macOS, aber auch diverse aus dem Open Source Lager, gibt es auch einige positive Beispiele, z.B. war ich eigentlich ganz zufrieden mit dem Gnome Calculator. Da ich allerdings Gnome nicht mehr benutze musste Ersatz her. Meinen inneren Drang alles selbst zu programmieren konnte ich glücklicherweise unterdrücken und meine Wahl viel auf SpeedCrunch.
SpeedCrunch ist eine QT-Anwendung und auf allen gängigen Plattformen verfügbar. Das Interface ist eher minimalistisch, standardmäßig werden gar keine Buttons für die Ziffern und Operatoren angezeigt, weil man das ja auch nicht braucht, die Berechnung kann wesentlich effizienter direkt über die Tastatur eingegeben werden.
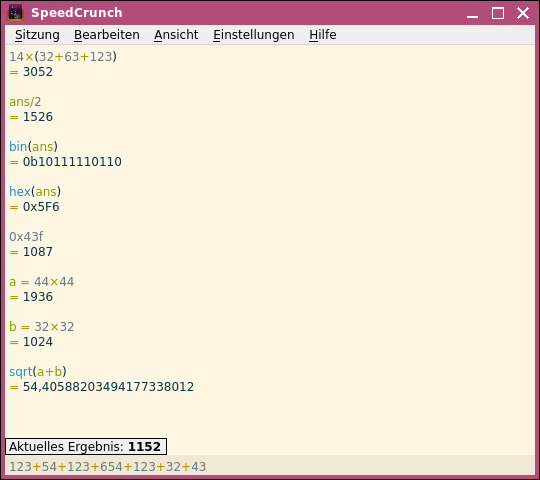
Praktischerweise hat man dann auch einen Verlauf der bisherigen Berechnungen.
Natürlich hat SpeedCrunch dann auch alle möglichen erweiterten Features: Variablen, Konstanten, Funktionen, Einheiten und eine Formelsammlung. Natürlich kann man auch Binär-, Oktal und Hexadezimalzahlen ein- und ausgeben.
Also insgesammt alle Features die man so braucht und mehr, verpackt in einem wesentlich sinnvolleren GUI-Konzept.
Installieren kann man SpeedCrunch auf vielen Distributionen direkt über die Paketverwaltung, ansonsten gibt es auf der Webseite Downloads.
Dieser Empfehlung kann ich mich nur anschließen.
Kontext
Ich habe ein neues XNEdit-Release veröffentlicht. XNEdit ist mein Fork des Editors NEdit, da dieser nicht mehr weiterentwickelt wird, aber wichtige Features wie Unterstützung für Unicode fehlen.
XNEdit 1.2 bringt einige GUI-Verbesserungen, hauptsächlich im Umgang mit Encodings und dem Öffnen von Dateien. So können nun z.B. Dateien aus Dateimanagern wie Nautilus per Drag'n'Drop geöffnet werden.
Ein wichtiges neues Feature ist außerdem, dass nun bei Encoding-Fehlern recht unkompliziert die Datei mit einer anderen Encoding neugeladen werden kann. Außerdem wurde auch die Erkennung der Encoding verbessert.
Damit hat sich hoffentlich der Umgang in XNEdit mit unterschiedlichen kodierten Dateien drastisch verbessert. Da ich selber praktisch nur UTF-8 nutze und auch alte Dateien schon lange konvertiert habe, hatte ich das bisher nicht so auf dem Schirm, wie nervig das sein kann.
XNEdit auf Sourceforge
Apache bezeichnet dies als milestone release, was wohl sowas wie eine Vorabversion oder ein Release Candidate ist.
Mit Tomcat 10 wird der Sprung von JEE 8 auf Jakarta EE 9 vollzogen, womit sich die Namespaces von javax.* auf jakarta.* ändern. Alte Anwendungen laufen ohne Anpassungen nicht mehr.
Um dieses Problem anzugehen, wird aktuell auch an einem Migrationstool gearbeitet, welches JEE8 Anwendungen automatisch in Jakarta EE Anwendungen konvertiert.
Apache Tomcat Webseite
Aus der beliebten Serie WTF C:
bool trigraphs_are_available() {
// Are trigraphs available??/
return false;
return true;
}
Was passiert hier? Zwei return-Statements hintereinander ergeben doch keinen Sinn! Kann die Funktion jemals true zurückgeben?
Auch dieses mal handelt es sich um standardkonformes C und es gibt auch Fälle, in denen die Funktion true liefert. Der Trick ist hier, dass im Kommentar etwas versteckt ist, nämlich am Ende ein Trigraph. Es ist nämlich in C möglich, manche Sonderzeichen durch alternative Zeichenketten auszudrücken. Am Ende des Kommentars steht der Trigraph ??/, der zu einem Backslash aufgelöst wird und ein Backslash am Ende eines einzeiligen Kommentars erweitert diesen auf die nächste Zeile. Wenn also der Compiler Trigraphen unterstützt, sind die ersten beiden Zeilen der Funktion ein Kommentar und übrig bleibt nur return true.
Gefunden habe ich das Beispiel hier.
Kommentare
dev | Artikel: Datei ver- und entschlüsseln mit openssl - kompatibel mit dav
Andreas | Artikel: Datenanalyse in der Shell Teil 1: Basis-Tools
Einfach und cool!
Danke Andreas
Rudi | Artikel: Raspberry Pi1 vs Raspberry Pi4 vs Fujitsu s920 vs Sun Ultra 45
Peter | Artikel: XNEdit - Mein NEdit-Fork mit Unicode-Support
Damit wird Nedit durch XNedit ersetzt.
Danke!
Olaf | Artikel: XNEdit - Mein NEdit-Fork mit Unicode-Support
Anti-Aliasing hängt von der Schriftart ab. Mit einem bitmap font sollte die Schrift klassisch wie in nedit aussehen.
Einfach unter Preferences -> Default Settings -> Text Fonts nach einer passenden Schriftart suchen.
Peter | Artikel: XNEdit - Mein NEdit-Fork mit Unicode-Support
Mettigel | Artikel: Raspberry Pi1 vs Raspberry Pi4 vs Fujitsu s920 vs Sun Ultra 45
Ich hatte gedacht, dass der GX-415 im s920 deutlich mehr Dampf hat als der Raspi4.
Mein Thinclient verbraucht mit 16 GB RAM ~11 W idle, das ist das Dreifache vom RP4. Das muss man dem kleinen echt lassen... Sparsam ist er.
Olaf | Artikel: Raspberry Pi1 vs Raspberry Pi4 vs Fujitsu s920 vs Sun Ultra 45
Ergebnisse von der Ultra 80 wären natürlich interessant, insbesondere im Vergleich mit dem rpi1.