Und womit macht ihr so eure Präsentationen? Powerpoint, Impress oder LaTeX? Wieso nicht mit Glade, das Klickibunti-Tool um GTK-Interfaces zusammenzubasteln. Ein paar Slides, oder ein GUI, wo ist da der Unterschied.
Die spannende Frage ist, ob man dann irgendwann mit Powerpoint GUI-Anwendungen designen kann. Das wäre doch der absolute Durchbruch. Direkt aus einer Bullshit-Präsentation eine App generieren.
Aber mal ernsthaft, egal womit man seine Präsentation erstellt, ich bin der Meinung, dass das Ausgabeformat immer pdf sein sollte. Das maximiert zum einen die Wahrscheinlichkeit, dass man es auf jedem Gerät fehlerfrei anzeigen kann, zum anderen kommt man gar nicht erst in die Versuchung mit Animationen zu arbeiten.
Die neue Armv8.5-A Architektur hat ein sehr interessantes neues Feature, nämlich Memory Tagging. Ein großer Teil heutiger Sicherheitslücken in Software ist auf Memory-Access-Fehler zurückzuführen, verursacht beispielsweise durch Bufferoverflows oder Use-after-free.
Memory Tagging soll dem entgegen wirken, indem Speicherbereichen und den dazugehörigen Pointern Tags zugeordnet werden. Nur wenn der Tag des Pointers dem des Speicherbereichs entspricht wird der Speicherzugriff gestattet.
Die Idee ist nicht neu, die SPARC M7 CPU hat das ähnliche Feature Silicon Secured Memory.
Jetzt gibt es natürlich auch Software-Profiling-Tools, die auch Speicherzugriffsfehler erkennen können, jedoch können die Programme damit schon mal 100 mal langsamer laufen. Mit Memory Tagging hingegen hat man praktisch keinen Performanceverlust und damit kann dies auch bei Software im Produktiveinsatz verwendet werden.
Insgesammt also ein sehr interessantes Feature, das hoffentlich auch von Intel und AMD eingeführt wird. Wer auch immer dies zuerst anbietet, könnte auf dem Servermarkt einen deutlichen Pluspunkt sammeln.
Xephyr ist ein X-Server, der die Ausgabe in einem Fenster eines anderen X-Servers darstellt. Ein nützliches Tool, wenn man z.B. einen Window-Manager entwickelt und diesen testen möchte ohne die eigene Desktop-Session zu beenden. Man kann Xephyr aber auch nutzen, um eine zweite Desktop-Session zu starten. Diese kann lokal sein, oder remote, für X11 spielt das keine Rolle.
Die Benutzung ist einfach. Zunächst startet man Xephyr und danach startet man einen beliebigen X-Client mit angepasster DISPLAY-Variable.
Xephyr :1 -ac -screen 800x600 &
DISPLAY=:1
xterm
Xephyr öffnet ein Fenster nur mit schwarzen Inhalt. Das ist die Ausgabe des zweiten X-Servers. Dieser enthält bisher nur ein Root-Window. Starten wir xterm auf diesem Display, fällt auf, dass es keine Window-Decoration oder sowas gibt. Denn das ist nur ein nacktes Root-Window mit Xterm als Kind, ganz ohne Window-Manager oder Desktop.
Es ist aber problemlos möglich, dort einfach einen Window-Manager zu starten, oder einen ganzen Desktop. Normalerweise haben Desktops ein Startprogramm dafür, was den Window-Manager und was sonst noch so benötigt wird, startet. Z.B. bei Gnome ist es gnome-session oder bei Xfce ist es xfce4-session.
Als Test hier ein Screenshot, wie ich den minimalen Window-Manager jwm innerhalb von Xephyr verwende.
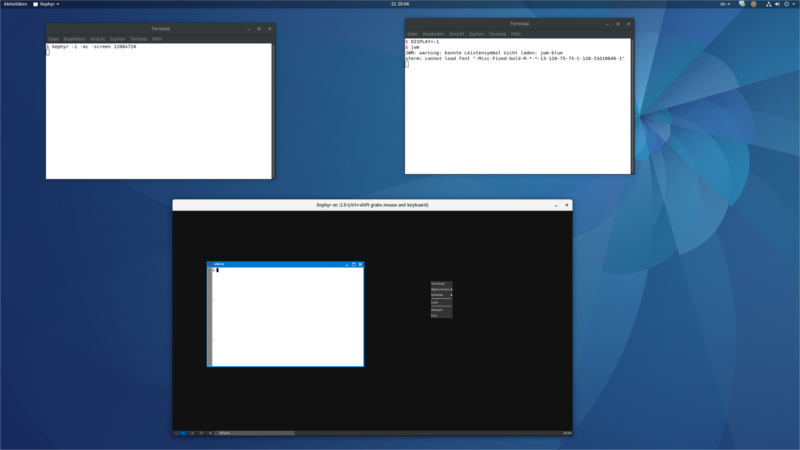
Es spricht auch nichts dagegen, per Remote-X11 einen X-Client zu starten. Auf diese weise kann man den Desktop einer entfernten Maschine lokal anzeigen.
DISPLAY=:1
ssh -X myhost gnome-session
Ein bisschen schöner wird es noch, wenn man Xephyr im Vollbild startet. Desweiteren hatte ich in Standardeinstellung Probleme mit dem Tastaturlayout, denn es ging die Alt-Graph-Taste nicht.
$ setxkbmap -query
rules: evdev
model: pc105
layout: de,de
variant: nodeadkeys,
options: compose:menu
$ Xephyr -keybd ephyr,,,xkbmodel=pc105,xkblayout=de,xkbrules=evdev -ac -fullscreen :1
Damit öffnet man Xephyr im Fullscreen-Modus mit dem Tastaturlayout des normalen X-Servers.
Ein weiteres Update für dav, diesmal mit zwei Bugfixes.
Durch einen Fehler im Code für den AES-Encryption-Stream konnte es unter ganz seltenen Fällen vorkommen, dass die letzten paar Bytes des Streams nicht geuploadet wurden. Beim Entschlüsseln machte sich dies dadurch bemerkbar, dass der Hash des Dateiinhalts nicht verifiziert werden konnte. Betroffen sind sowohl dav als auch dav-sync.
Der zweite Bug betrifft dav-sync. Der Befehl push hat beim Löschen von Collections auf dem Server nicht überprüft, ob diese Collections irgendwelche neuen oder modifizierten Kind-Ressourcen enthalten. Dies wurde behoben, was jedoch auf Kosten der Performance beim Löschen geht.
dav Projektseite
SourceForge Projektseite
Nach dem ich bereits schon mal meine Zweifel über die Kühlung in Macs geäußert hatte, hat mich dieser Artikel bei Golem in meiner Meinung wieder einmal bestätigt. Das neue Macbook Pro mit Core i9 kann die CPU nicht mal ansatzweise vernünftig kühlen. Dabei betreibt Apple die CPUs schon beim obersten Temperatur-Limit, bevor das Gerät nur eine Pfütze Aluminium wird, und selbst dann muss schon kräftig gedrosselt werden.
Mehr denn je ist Apples Motto Function follows Form. Leider gibt es immer noch zu viele Fanboys, die Apple-Produkte mit Qualität verbinden. Die sehr hohen Preise werden dadurch gerechtfertigt, dass man dafür schließlich ein hochwertiges Produkt erhält. Dabei gibt es kaum ein neues Apple-Produkt ohne katastrophale Fehler. Dieses Video listet einige auf. Mein Favorit sind die Lüfter, die den Kleber des zusammengefrickelten (angeblichen Unibody) Gehäuse lösen.
Ein Fehler den viele begehen ist, dass sie das Macbook Pro mit billigen Consumer-Schrott für 400€ vergleichen, und da sieht das Macbook vielleicht hochwertig aus. Dabei wird vergessen, dass es auch PC-Hardware von den großen Herstellern (Lenovo, Dell, HP, Fujitsu) in ähnlichen Preisregionen wie bei Apple gibt, die dann aber dem Macbook in Qualität und Ausstattung haushoch überlegen sind.
Kommentare
dev | Artikel: Datei ver- und entschlüsseln mit openssl - kompatibel mit dav
Andreas | Artikel: Datenanalyse in der Shell Teil 1: Basis-Tools
Einfach und cool!
Danke Andreas
Rudi | Artikel: Raspberry Pi1 vs Raspberry Pi4 vs Fujitsu s920 vs Sun Ultra 45
Peter | Artikel: XNEdit - Mein NEdit-Fork mit Unicode-Support
Damit wird Nedit durch XNedit ersetzt.
Danke!
Olaf | Artikel: XNEdit - Mein NEdit-Fork mit Unicode-Support
Anti-Aliasing hängt von der Schriftart ab. Mit einem bitmap font sollte die Schrift klassisch wie in nedit aussehen.
Einfach unter Preferences -> Default Settings -> Text Fonts nach einer passenden Schriftart suchen.
Peter | Artikel: XNEdit - Mein NEdit-Fork mit Unicode-Support
Mettigel | Artikel: Raspberry Pi1 vs Raspberry Pi4 vs Fujitsu s920 vs Sun Ultra 45
Ich hatte gedacht, dass der GX-415 im s920 deutlich mehr Dampf hat als der Raspi4.
Mein Thinclient verbraucht mit 16 GB RAM ~11 W idle, das ist das Dreifache vom RP4. Das muss man dem kleinen echt lassen... Sparsam ist er.
Olaf | Artikel: Raspberry Pi1 vs Raspberry Pi4 vs Fujitsu s920 vs Sun Ultra 45
Ergebnisse von der Ultra 80 wären natürlich interessant, insbesondere im Vergleich mit dem rpi1.