Wer eine plattformunabhängige Lösung für den Zugriff auf Extended Attributes benötigt, für den habe ich hier eine kleine "Bibliothek", bestehend aus einer .c und einer .h Datei. Lizenz ist 0BSD, daher kann jeder den Code verwenden wie er will.
Aktuell werden Linux, FreeBSD, Solaris und macOS unterstützt. Eine Implementierung, die unter Windows Alternate Data Streams verwendet, kommt vermutlich noch.
WsgiDAV ist ein in Python geschriebener WebDAV-Server, der sowohl stand-alone über HTTP oder über WSGI in Kombination mit einem Webserver verwendet werden kann. Die Feature-Liste beinhaltet:
- Vollständige WebDAV-Implementierung inklusive Support für Locking und Properties
- Authentifizierung über PAM, AD oder über einfach in der Konfigurationsdatei hinterlegte Benutzer
- Extrabehandlungen für einige Anwendungen, z.B. MS Office
- Erweiterbarkeit/Plugin-Schnittstelle
Was mich natürlich interessiert ist, ob Dead Properties richtig funktionieren und XML-Namespaces korrekt behandelt werden (nicht so wie bei anderen). Dazu habe ich aus dem WebDAV-RFC den Beispiel-Request aus Section 9.2.2 ausgeführt.
<?xml version="1.0" encoding="utf-8" ?>
<D:propertyupdate xmlns:D="DAV:"
xmlns:Z="http://ns.example.com/standards/z39.50/">
<D:set>
<D:prop>
<Z:Authors>
<Z:Author>Jim Whitehead</Z:Author>
<Z:Author>Roy Fielding</Z:Author>
</Z:Authors>
</D:prop>
</D:set>
<D:remove>
<D:prop><Z:Copyright-Owner/></D:prop>
</D:remove>
</D:propertyupdate>
Dieser speichert eine Property mit XML-Werten, die Namespace-Definition dazu ist allerdings im Root-Element, nicht im Property-Element Z:Authors. Einige Server-Implementierungen haben mit dieser Art Request Probleme. WsgiDAV hingegen verarbeitet dies problemlos. Man muss allerdings dazu sicherstellen, dass Dead Properties aktiviert sind und persistent gespeichert werden. Dazu muss der property_manager konfiguriert sein:
# Property Manager
# null: (default) no support for dead properties
# true: Use wsgidav.prop_man.property_manager.PropertyManager
# which is an in-memory property manager (NOT persistent)
#
# Example: Use persistent shelve based property manager
property_manager:
class: wsgidav.prop_man.property_manager.ShelvePropertyManager
kwargs:
storage_path: 'wsgidav-props.shelve'
Ein anderer Test von mir war dav-sync. Auch dies funktioniert problemlos. Bisher war meine Empfehlung für einen Server für dav-sync in der Regel Apache. Wer einen anderen Webserver benutzt, dem kann ich hiermit jetzt WsgiDAV empfehlen.
Es sieht so aus als könnte es eine Klage gegen GitHubs Copilot geben. Matthew Butterick, ein Programmierer und Anwalt, scheint dies in Erwägung zu ziehen.
GitHub Copilot ist ein Tool, welches Code-Vorschläge im Editor generiert. Die dahinterstehende KI wurde mit Open-Source-Code von GitHub trainiert. Dabei stellt sich zum einen die Frage, ob die KI-Trainingsdaten ein von den Open-Source-Projekten abgeleitetes Werk sind, zum anderen ist das Copyright des generierten Codes auch unklar, da dieser teilweise unverändert aus den GitHub-Projekten übernommen wird. Wenn man fremden Open-Source-Code übernimmt, muss man die Lizenzbedingungen beachten, daher bei Lizenzen wie der GPL muss der eigene Code auch unter einer kompatiblen Lizenz veröffentlicht werden und generell muss fast immer das Copyright des fremden Codes mit angegeben werden. GitHub Copilot unterschlägt hingegen meistens die Copyright-Hinweise oder kann auch ein falsches Copyright angeben.
Microsoft scheint den juristischen Fragen bezüglich GitHub Copilot bisher aus dem Weg zu gehen. Die Verantwortung wird auf den Copilot-Benutzer geschoben.
You are responsible for ensuring the security and quality of your code. We recommend you take the same precautions when using code generated by GitHub Copilot that you would when using any code you didn't write yourself. These precautions include rigorous testing, IP scanning, and tracking for security vulnerabilities.
Juristisch ist das Thema bisher ungeklärt. Wer selber GitHub Copilot benutzt, sollte sich darüber im Klaren sein.
Privat benutze ich seit einer ganzen Weile primär FreeBSD und auch schon ewig benutze ich für die Benutzerauthentifizierung LDAP. Leider hatte Thunderbird mit genau dieser Konstellation Probleme und direkt beim Starten gab es einen Crash. Mit normalen lokalen Benutzern hingegen lief Thunderbird problemlos. Ich habe dazu auch ein paar Bug-Reports gefunden, die angeblich auch gefixt sind. Aber bis vor kurzem ging es definitiv noch nicht.
Aber jetzt habe ich es mal wieder getestet und siehe da, es funktioniert! Es geschehen offenbar doch noch Wunder.
Mal angenommen man hat eine Textdatei in XNEdit geöffnet, in der sich im Text eine URL befindet, die man bequem öffnen möchte. Zugegeben, die URL kopieren und im Browser öffnen ist jetzt nicht wahnsinnig schwierig, aber es geht minimal einfacher.
Die Idee ist ein kurzes Makro, welches den ausgewählten Text an xdg-open übergibt. Das Makro kann dann im Makro- oder Background-Menü hinterlegt werden (Preferences -> Default Settings -> Customize Menus).
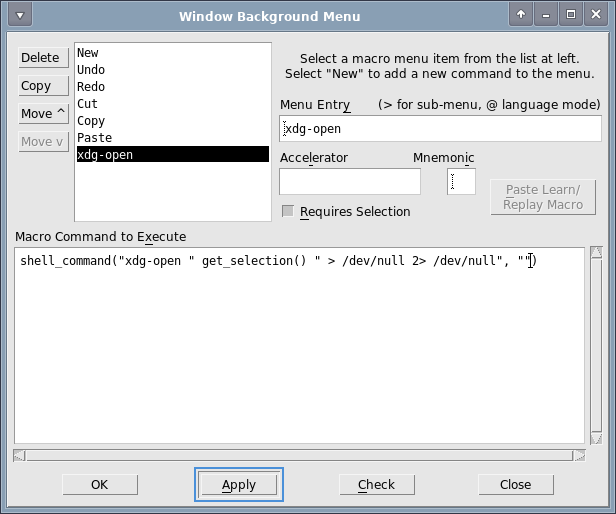
Macro Command:
shell_command("xdg-open " get_selection() " > /dev/null 2> /dev/null", "")
Wichtig ist, dass Requires Selection angekreuzt ist.
Danach reicht es die URL zu markieren und das Makro auszuführen (Rechtsklick für das Backgroundmenu oder man konfiguriert auch einen Accelerator). Das Ganze funktioniert nicht nur mit URLs, sondern mit allem, was von xdg-open geöffnet werden kann, z.B. auch Email-Adressen.
Kommentare
Andreas | Artikel: Datenanalyse in der Shell Teil 1: Basis-Tools
Einfach und cool!
Danke Andreas
Rudi | Artikel: Raspberry Pi1 vs Raspberry Pi4 vs Fujitsu s920 vs Sun Ultra 45
Peter | Artikel: XNEdit - Mein NEdit-Fork mit Unicode-Support
Damit wird Nedit durch XNedit ersetzt.
Danke!
Olaf | Artikel: XNEdit - Mein NEdit-Fork mit Unicode-Support
Anti-Aliasing hängt von der Schriftart ab. Mit einem bitmap font sollte die Schrift klassisch wie in nedit aussehen.
Einfach unter Preferences -> Default Settings -> Text Fonts nach einer passenden Schriftart suchen.
Peter | Artikel: XNEdit - Mein NEdit-Fork mit Unicode-Support
Mettigel | Artikel: Raspberry Pi1 vs Raspberry Pi4 vs Fujitsu s920 vs Sun Ultra 45
Ich hatte gedacht, dass der GX-415 im s920 deutlich mehr Dampf hat als der Raspi4.
Mein Thinclient verbraucht mit 16 GB RAM ~11 W idle, das ist das Dreifache vom RP4. Das muss man dem kleinen echt lassen... Sparsam ist er.
Olaf | Artikel: Raspberry Pi1 vs Raspberry Pi4 vs Fujitsu s920 vs Sun Ultra 45
Ergebnisse von der Ultra 80 wären natürlich interessant, insbesondere im Vergleich mit dem rpi1.
kosta | Artikel: Raspberry Pi1 vs Raspberry Pi4 vs Fujitsu s920 vs Sun Ultra 45
ich hätt hier zugriff auf Ultra-80 4CPU 4GB 2x Elite3D.